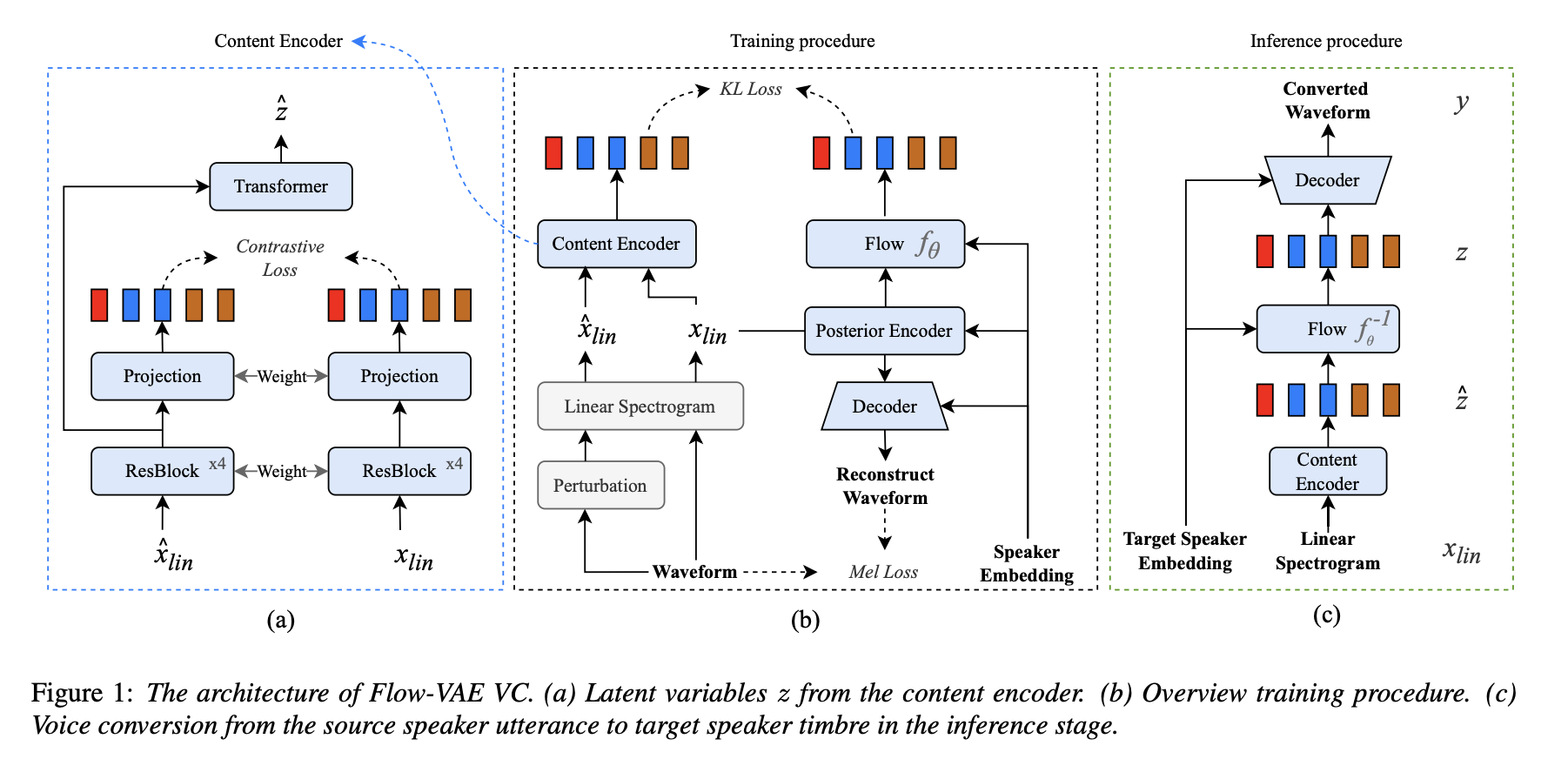
Flow-VAE VC: End-to-End Flow Framework with Contrastive Loss for Zero-shot Voice Conversion
Abstract
Voice conversion (VC) seeks to modify one speaker's voice to generate speech as if it came from
another speaker. It is
challenging especially when source and target speakers are unseen during training (zero-shot VC).
Recent work in this
area made progress with disentanglement methods that separate utterance content and speaker
characteristics from speech
audio recordings. However, these models either lack adequate disentanglement ability or rely on the
use of a trained
vocoder to reconstruct the speech from acoustic features. We propose Flow-VAE VC, which is an
end-to-end system
processing directly on the raw audio waveform for zero-shot tasks. Flow-VAE VC adopts a conditional
Variational
Autoencoder (VAE) with normalizing flows and an adversarial training process to improve the
expressive power of
generative modeling. Specifically, we learn context-invariant representations by applying
frame-level contrastive loss
to speech different augment samples. The experiments show that the proposed method achieves a decent
performance on
zero-shot voice conversion and significantly improves converted speech naturalness and speaker
similarity.